
Quantitative Data
Feature
In OpenMS, information about quantitative data is stored in a so-called
Feature which we have previously discussed here. Each
Feature represents a region in RT and m/z space use for quantitative
analysis.
1from pyopenms import *
2feature = Feature()
3feature.setMZ( 500.9 )
4feature.setCharge(2)
5feature.setRT( 1500.1 )
6feature.setIntensity( 30500 )
7feature.setOverallQuality( 10 )
Usually, the quantitative features would be produced by a so-called
“FeatureFinder” algorithm, which we will discuss in the next chapter. The
features can be stored in a FeatureMap and written to disk.
1fm = FeatureMap()
2fm.push_back(feature)
3feature.setRT(1600.5 )
4feature.setCharge(2)
5feature.setMZ( 600.0 )
6feature.setIntensity( 80500.0 )
7fm.push_back(feature)
8FeatureXMLFile().store("test.featureXML", fm)
Visualizing the resulting map in TOPPView allows detection of the two
features stored in the FeatureMap with the visualization indicating charge
state, m/z, RT and other properties:

Note that in this case only 2 features are present, but in a typical LC-MS/MS experiments, thousands of features are present.
FeatureMap
The resulting FeatureMap can be used in various ways to extract
quantitative data directly and it supports direct iteration in Python:
1fmap = FeatureMap()
2FeatureXMLFile().load("test.featureXML", fmap)
3for feature in fmap:
4 print("Feature: ", feature.getIntensity(), feature.getRT(), feature.getMZ())
ConsensusFeature
Often LC-MS/MS experiments are run to compare quantitative features across
experiments. In OpenMS, linked features from individual experiments are
represented by a ConsensusFeature
1feature = ConsensusFeature()
2feature.setMZ( 500.9 )
3feature.setCharge(2)
4feature.setRT( 1500.1 )
5feature.setIntensity( 80500 )
6
7# Generate ConsensusFeature and features from two maps (with id 1 and 2)
8### Feature 1
9f_m1 = ConsensusFeature()
10f_m1.setRT(500)
11f_m1.setMZ(300.01)
12f_m1.setIntensity(200)
13f_m1.ensureUniqueId()
14### Feature 2
15f_m2 = ConsensusFeature()
16f_m2.setRT(505)
17f_m2.setMZ(299.99)
18f_m2.setIntensity(600)
19f_m2.ensureUniqueId()
20feature.insert(1, f_m1 )
21feature.insert(2, f_m2 )
We have thus added two features from two individual maps (which have the unique
identifier 1 and 2) to the ConsensusFeature.
Next, we inspect the consensus feature, compute a “consensus” m/z across
the two maps and output the two linked features:
1# The two features in map 1 and map 2 represent the same analyte at
2# slightly different RT and m/z
3for fh in feature.getFeatureList():
4 print(fh.getMapIndex(), fh.getIntensity(), fh.getRT())
5
6print(feature.getMZ())
7feature.computeMonoisotopicConsensus()
8print(feature.getMZ())
9
10# Generate ConsensusMap and add two maps (with id 1 and 2)
11cmap = ConsensusMap()
12fds = { 1 : ColumnHeader(), 2 : ColumnHeader() }
13fds[1].filename = "file1"
14fds[2].filename = "file2"
15cmap.setColumnHeaders(fds)
16
17feature.ensureUniqueId()
18cmap.push_back(feature)
19ConsensusXMLFile().store("test.consensusXML", cmap)
Inspection of the generated test.consensusXML reveals that it contains
references to two LC-MS/MS runs (file1 and file2) with their respective
unique identifier. Note how the two features we added before have matching
unique identifiers.
Visualization of the resulting output file reveals a single
ConsensusFeature of size 2 that links to the two individual features at
their respective positions in RT and m/z:
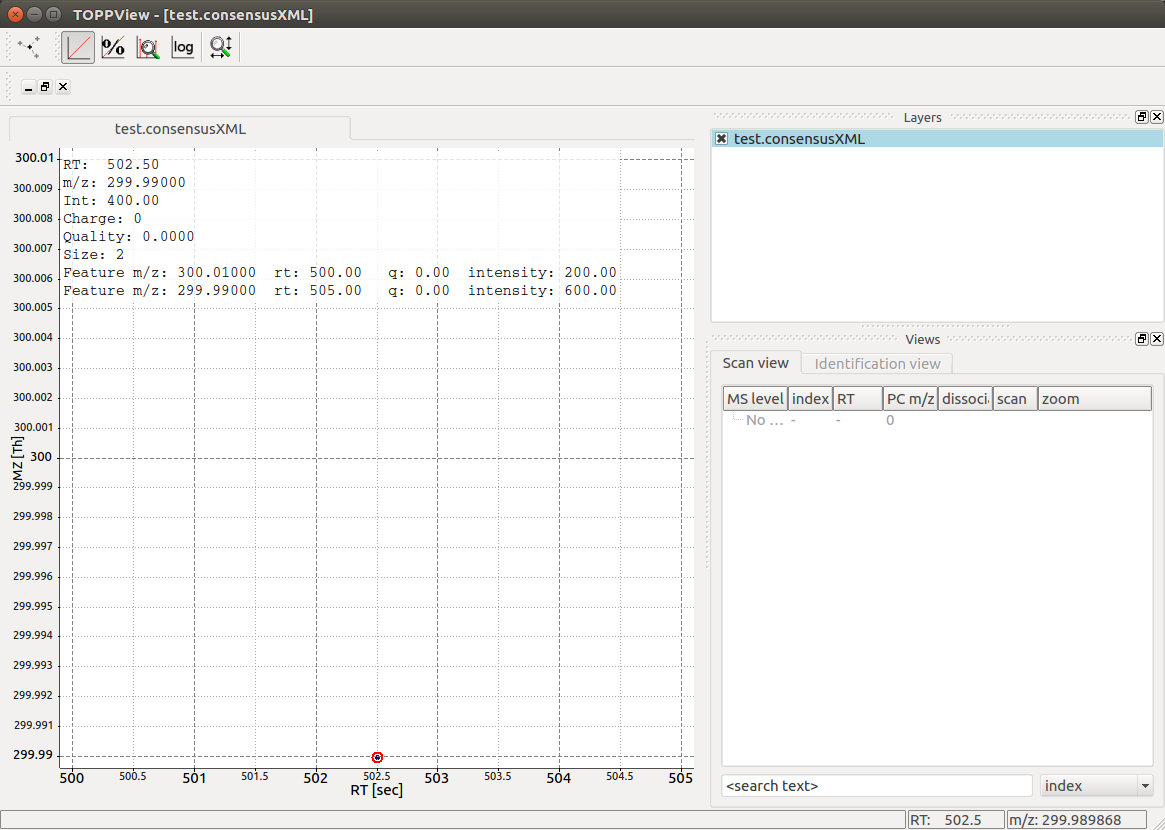
ConsensusMap
The resulting ConsensusMap can be used in various ways to extract
quantitative data directly and it supports direct iteration in Python:
1cmap = ConsensusMap()
2ConsensusXMLFile().load("test.consensusXML", cmap)
3for cfeature in cmap:
4 cfeature.computeConsensus()
5 print("ConsensusFeature", cfeature.getIntensity(), cfeature.getRT(), cfeature.getMZ())
6 # The two features in map 1 and map 2 represent the same analyte at
7 # slightly different RT and m/z
8 for fh in cfeature.getFeatureList():
9 print(" -- Feature", fh.getMapIndex(), fh.getIntensity(), fh.getRT())